网络模型定义
Kubernetes 网络模型定义:
- **每个 Pod 都有自己的 IP 地址。**无需在 Pod 之间创建链接,也无需将容器端口映射到主机端口。
- 节点上的 Pod 可以在没有 NAT 的情况下与所有节点上的所有 Pod 进行通信。
- 一个节点上的 Pod 可以在没有 NAT 的情况下与所有节点上的所有 Pod 通信。
- 节点上的代理(例如系统守护进程,Kubelet)可以与该节点中的所有pod进行通信。
- Pod 中的容器共享它们的网络命名空间(IP 和 MAC 地址),因此可以使用环回地址相互通信。
Kubernetes 网络解决了四个问题:
- 容器到容器网络互通
- Pod到Pod 网络互通
- Pod到Service间的网络互通
- 公网到Service间网络互通
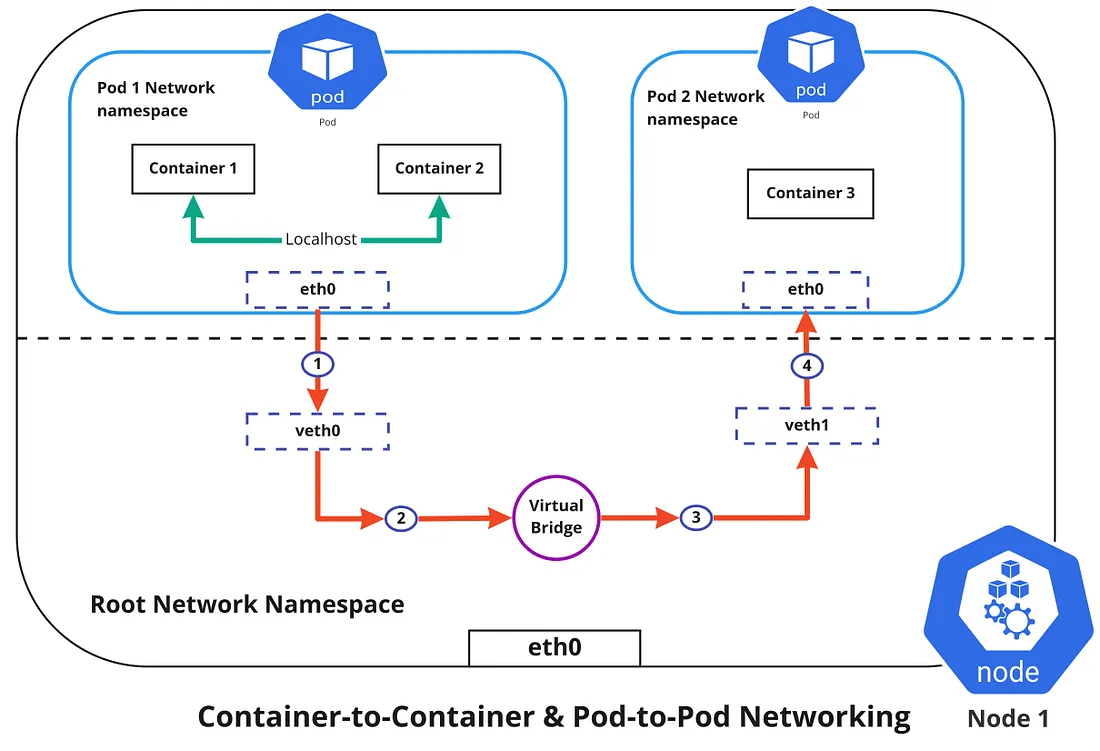
容器到容器的网络
容器到容器网络通过 Pod 网络命名空间进行。网络命名空间允许我们拥有单独的网络接口和路由表,这些接口和路由表与系统的其余部分隔离,并且可以独立运行。每个 Pod 都有自己的网络命名空间,容器内部 Pod 共享相同的 IP 地址和端口。这些容器之间的所有通信都将通过 localhost 进行,因为它们都是同一命名空间的一部分。( 用图中的绿线表示 )
Pod到Pod的网络
在 Kubernetes 中,每个节点都有一个为 Pod 指定的 CIDR IP 范围。这将确保每个 Pod 获得一个唯一的 IP 地址,集群中的其他 Pod 可以看到该地址,并确保在创建新 Pod 时,IP 地址永远不会重叠。与容器到容器网络不同,无论 Pod 是部署在同一节点上还是集群中的不同节点上,Pod 到 Pod 的通信使用真实的 IP 进行。
从上图中可以看出,要使 Pod 相互通信,流量必须在 Pod 网络命名空间和根网络命名空间之间流动。这是通过虚拟以太网设备或 veth 对(图中的 veth0 到 Pod 命名空间 1,veth1 到 Pod 命名空间 2)连接 Pod 命名空间和根命名空间来实现的。这两个虚拟接口将通过虚拟网络桥连接,然后允许流量使用ARP协议在它们之间流动。
因此,如果数据从 Pod 1 发送到 Pod 2,则事件流将如下所示(参见上图)
- Pod 1 流量通过 eth0 流向根网络命名空间虚拟接口 veth0。
- 然后流量通过 veth0 到达连接到 veth1 的虚拟网桥。
- 流量通过虚拟桥到达 veth1
- 最后,流量通过 veth1 到达 Pod 2 的 eth0 接口。
Pod到Service的网络
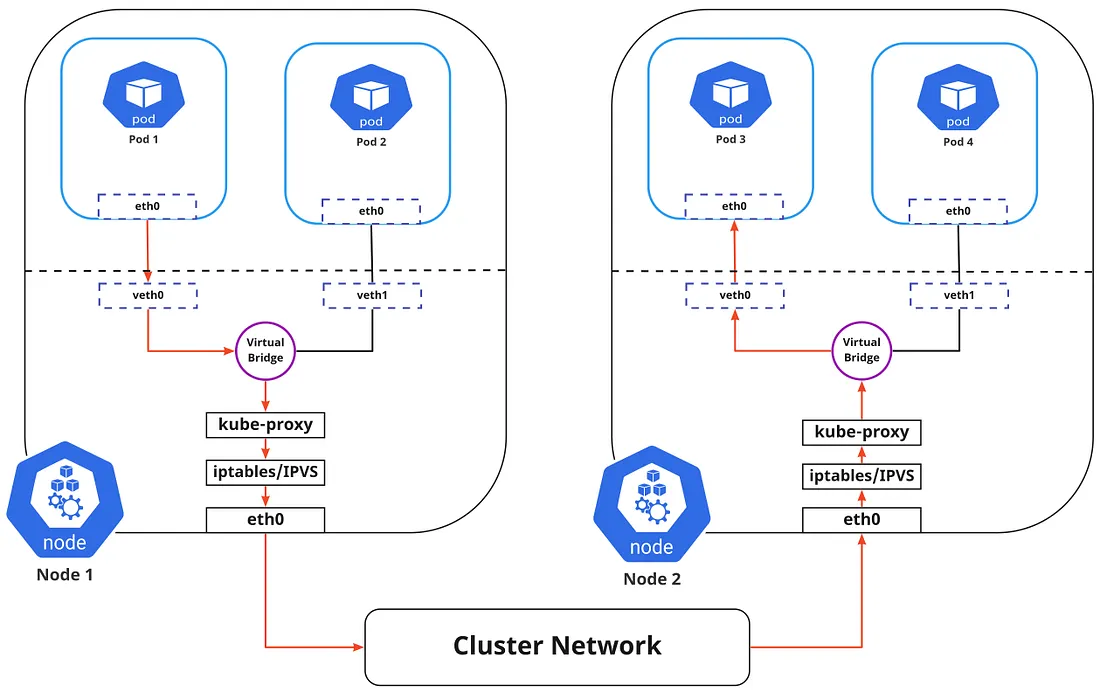
Pod本质上是非常动态的。他们可能需要根据需求进行扩展或缩减。如果应用程序崩溃或节点故障,可以再次创建它们。所有这些事件都会导致 Pods IP 地址更改,这使得网络成为一项挑战。
Kubernetes 通过使用 Service 解决了这个问题。那么,这项服务究竟负责什么呢?
- 在前端分配一个静态虚拟 IP 地址,用于连接与服务关联的任何后端 Pod。
- 对发往此虚拟 IP 的任何流量到支持 Pod 集进行负载平衡。
- 跟踪 Pod 的 IP 地址,因此即使 Pod IP 地址发生更改,客户端在连接到 Pod 时也不会遇到任何问题,因为它们只能直接与服务本身的静态虚拟 IP 地址连接。
可以通过两种方式完成群集内负载平衡:
- IPTABLES:在此模式下,kube-proxy 监视 API 服务器中的更改,并且对于每个新服务,它都会安装 iptables 规则,这些规则捕获到服务集群 IP 和端口的流量,这会将该流量重定向到此服务的后端 Pod。Pod 是随机选择的。此模式更可靠,并且具有较低的系统开销,因为流量由 Linux Netfilter 处理,而无需在用户空间和内核空间之间切换。( 参考 — iptables 代理模式 )
- IPVS:IPVS 建立在 Netfilter 之上,实现了传输层负载平衡。IPVS 使用 netfilter hook 函数,使用哈希表作为底层数据结构,并在内核空间中工作。这意味着与 iptables 模式下的 kube 代理相比,IPVS 模式下的 kube 代理将以更低的延迟、更高的吞吐量和更好的性能重定向流量。( 参考 — IPVS 代理模式 )
我在这里发现了一个有趣的阅读比较 kube-proxy 模式 — iptables vs ipvs
包从 Pod 1 到 Pod 3 的流经服务流向另一个节点,如上图所示(标记为红色)。请注意,前往虚拟网桥的软件包必须通过默认路由(eth0)进行路由,因为在网桥上运行的ARP协议无法理解服务,并且稍后它们将被iptables过滤,而iptables反过来将使用kube-proxy在节点中定义的规则。因此,该图直接显示路径的原样。
Internet到Service的网络
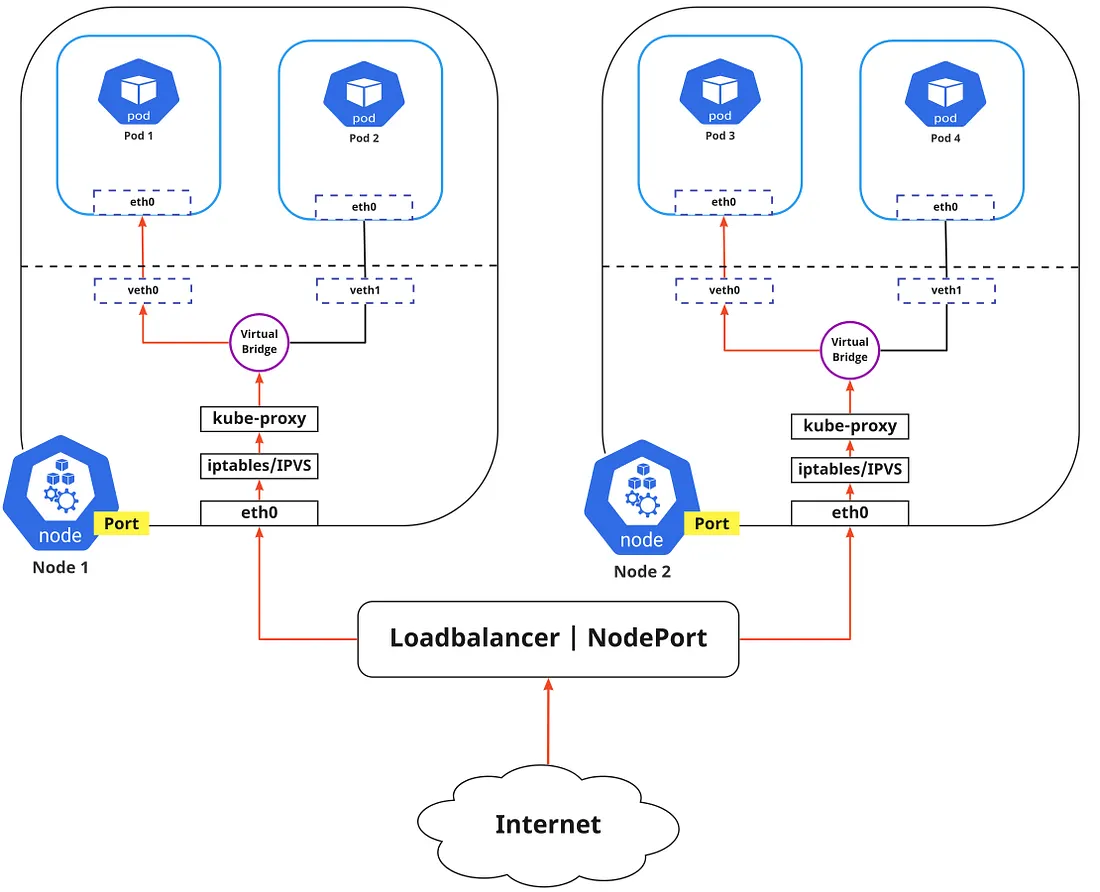
到目前为止,我们已经讨论了如何在集群内路由流量。 现在,如果我们需要将应用程序暴露给外部网络,我们可以通过两种方式做到这一点:
- Egress:这是您想要将来自 Kubernetes 服务的流量路由到 Internet 的时候。 在这种情况下,iptables 将执行源 NAT,因此流量似乎来自节点而不是 pod。
- Ingress: 这是来自外部世界的服务的传入流量。 Ingress 还使用一组连接规则允许和阻止与服务的特定通信。 通常,有两种入口解决方案在不同的网络堆栈区域上运行:服务负载均衡器和入口控制器
服务发现:
There are two ways in which Kubernetes can discover a Service:
Kubernetes 可以通过两种方式发现服务:
- Environment Variables: 在 Pod 运行的节点上运行的 kubelet 服务负责为每个活动服务设置环境变量,格式为 {SVCNAME}_SERVICE_HOST & {SVCNAME}_SERVICE_PORT。 请注意,您必须在客户端 Pod 出现之前创建服务。 否则,这些客户端 Pod 将不会填充其环境变量。
- DNS: DNS 服务被实现为 Kubernetes 服务,它映射到一个或多个 DNS 服务器 pod,这些 pod 像任何其他 pod 一样被调度。 集群中的 Pod 被配置为使用 DNS 服务,DNS 搜索列表包括 Pod 自己的命名空间和集群的默认域。 一个集群感知 DNS 服务器,例如 CoreDNS,监视 Kubernetes API 的新服务并为每个服务创建一组 DNS 记录。 如果在整个集群中启用了 DNS,那么所有 Pod 应该能够自动通过其 DNS 名称解析服务。 Kubernetes DNS 服务器是访问 ExternalName Services 的唯一途径。( Refer — DNS for Services and Pods )
发布服务的服务类型:
Kubernetes 服务为我们提供了一种访问一组 Pod 的方法,这些 Pod 通常可以使用标签选择器进行定义。这可能是应用程序尝试访问集群中的其他应用程序,也可能是允许我们向外部世界公开集群中运行的应用程序。Kubernetes ServiceTypes 允许您指定所需的服务类型。
不同的服务类型有:
- ClusterIP:这是默认的ServiceType。 这使得服务只能从集群内访问,并允许集群内的应用程序相互通信。 没有外部访问。
- LoadBalancer:此 ServiceType 使用云提供商的负载均衡器向外部公开服务。 来自外部负载均衡器的流量被定向到后端 Pod。 云提供商决定如何进行负载平衡。
- NodePort:这允许外部流量通过在所有节点上打开特定端口来访问服务。 任何发送到此端口的流量都会被转发到服务。
- ExternalName:这种类型的服务通过使用 externalName 字段的内容通过返回带有其值的 CNAME 记录来将服务映射到 DNS 名称。 没有设置任何类型的代理。