Kubernetes 共享 GPU 调度指南
· 25 min read
本篇博文介绍了如何在 Kubernetes 集群中使用 GPU 资源,以及如何设置共享 Nvidia GPU 的详细步骤。
依照本文操作你将完成如下内容:
- Nvidia 和 CUDA 驱动安装
- Nvidia Container Runtime 的配置
- Kubernetes 通过 GPU plugin 实现 GPU 调度支持
- Kubernetes 开启共享 Nvidia GPU 资源配置
本篇博文介绍了如何在 Kubernetes 集群中使用 GPU 资源,以及如何设置共享 Nvidia GPU 的详细步骤。
依照本文操作你将完成如下内容:
随着时间的推移,Prometheus 中存储的指标数量越来越多,查询的频率也越来越高。随着越来越多的仪表板被添加到 Grafana,我开始遇到 Grafana 无法按时呈现图形和 Prometheus 查询超时的情况,尤其在长时间聚合大量指标时这种现象更为严重。
本文用到了 Prometheus Recording Rule 实现对高维度指标查询的 PromQL 语句的性能优化,提高查询效率。
现在安装 Kubernetes 集群已经变得越来越简单了,Kubernetes in Docker(KinD)这个工具就可以通过创建容器来作为 Kubernetes 的节点,我们只需要在机器上安装 Docker 就可以使用,它允许我们在很短的时间内就启动一个多节点的集群,而不依赖任何其他工具或云服务商。
本文将介绍 Kind 中 extra-port-mappings,kubernetes-version,image-registry,api-server-acl 等基本配置。 并带有一个 kubesphere 部署示例,还演示了在不删除 Kind 集群的情况下的暂停和重启,以及 Kind 开启 IPVS 导致相关错误的排查记录。
External-DNS 简化了 DNS 记录的管理,它通过监视 Kubernetes 资源,并利用外部 DNS 提供商来配置相应的 DNS 记录。
本文介绍如何部署 External-DNS ,并通过示例验证其功能特性。
Cert-Manager 是 Kubernetes 上的全能证书管理工具,本文将介绍如何使用 Cert-Manager 的 ACME Issuer 进行申请免费证书并为证书自动续期。
Kubernetes 于 2014 年夏季登陆 GitHub ,2015 年夏季推出 Kubernetes 的第一个 1.0 版本,其发展速度和进步在许多人的脑海中仍然记忆犹新。
像任何应用基础设施一样,workloads 的操作开始在 Kubernetes 上变得越来越重要。所以 Kubernetes 提出了 resources 的概念,通常由基于 YAML 的 manifests 来描述各种各样的 workloads,如 deployment.yaml。
随着需要部署的 manifests 数量和需要维护的 Kubernetes 集群数量的双重增加,我们需要更高效的 manifests 管理方式,以便在 cluster-to-cluster 之间获得更容易的部署,和更灵活的配置。
本文将介绍如何使用 Heml 和 Kustomize 来对 Kubernetes 生态系统内的对象进行声明式配置和包管理。
集群内的应用有时候需要调用外部的服务,我们知道集群内部服务调用都是通过 Service 互相访问,那么针对外部的服务是否也可以保持统一使用 Service 呢?
答案是肯定的,通过 Service 访问外部服务,除了方式统一以外,还能带来其他好处。如应用配置统一,可以通过 Service 映射保持两边配置统一,实现不同环境的应用通过相同 Service Name 访问不同的外部数据库。
如图 test-1 和 test-2 两个空间为两个不同的业务环境,通过服务映射,不同空间相同的 Service 访问到对应外部不同环境的数据库:
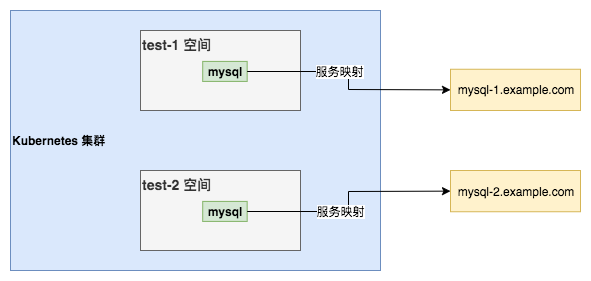
另外,还可以保证最小化变更,如果外部数据库 IP 之类的变动,只需要修改 Service 对应映射即可,服务本身配置无需变动。